The worst part of reverse engineering C++ programs -- or really, any program that uses custom structure types with no definitions provided -- is that information about structures is often incomplete, sporadic, and isolated. Consider the following function:

From this code, we can infer that rcx points to a struct that has a QWORD-sized field at offset +0x70. However, from this code alone, we don't know:
- The true type of the field at offset
+0x70; - The types and locations of any other fields;
- How big the
structis; - Where else in the program the
structis used; - Whether the
structcontains any otherstructs, or is contained in any otherstructs.
The most precise struct we can infer based upon this evidence is:
struct sub_180013E60_arg_0 {
char gap0[0x70];
_QWORD qw70;
};To obtain more information about the struct, we would need to go on a scavenger hunt looking at the callers of sub_180013E60 and following the pointer around the code to find other accesses. This procedure can easily lead to dead-ends, where the pointer is read from or written to another memory location, and we have no easy way of knowing what other parts of the code access that memory location; or if the function or its callers were declared virtual and hence called indirectly. In short, structure recovery is a tedious process that involves working with incomplete information most of the time, and gradually refining that information by finding other uses of the same structure type.
This blog entry describes an overlooked source of information in C++ programs that can make manual and automated type reconstruction more efficient. More information about the data types used within a function is hiding in plain sight; we can exploit it if we simply know where to look and how to interpret it.
Hex-Rays 9.0 contains built-in support to display this information -- namely, C++ exception wind and unwind metadata on MSVC/x64 targets -- naturally and automatically, directly in the decompilation listing.
Background: C++ Exception Support
Like other programming languages, C++ supports the notion of exceptions. The three relevant language keywords are throw, try, and catch. (Standard C++ does not have a finally keyword.)
Upon encountering an exceptional situation, C++ code can use the throw keyword to raise a new exception. For example, consider the following function:
void may_throw() {
if ( rand() & 1 )
throw std::runtime_error("You lose");
}C++ code uses the try keyword to create a scope in which an exception may occur. try scopes have one or more catch blocks to catch specific types of exceptions. For example:
try {
may_throw();
printf("No exception\n");
}
catch ( std::runtime_error &r ) {
printf("Caught standard runtime_error %s\n", r.what());
}
catch ( std::exception &e ) {
printf("Caught standard exception %s\n", e.what());
}
catch ( ... ) {
printf("Caught any exception\n");
}A catch handler might decide that, despite catching an exception, it is unable to handle it, and that the exception should be passed to the next catch handler (or to the next try block if no remaining catch handler can process it). Using the keyword throw by itself will propagate the exception as such. For example:
try {
may_throw();
printf("No exception\n");
}
catch ( std::runtime_error &r ) {
printf("Can't handle standard runtime_error %s\n", r.what());
throw; // <- HERE: let the next handler try to process it
}Hex-Rays 9.0 Support
I have spent all of 2024 implementing C++ exception metadata for MSVC/x64 into Hex-Rays 9.0. It is capable of representing try and catch blocks, including nested ones, as such:

Or try blocks with multiple catch handlers:

(Note that early beta "releases" suffered from issues that would often prevent their display; these issues have been remedied in advance of the eventual full release.)
However, this blog entry is about a different kind of C++ exception metadata: namely, wind and unwind. In the remainder of this blog entry, we introduce wind and unwind metadata -- what it is, and when and why the compiler inserts it -- before describing how to exploit it when reverse engineering C++ programs.
C++ Object Model: Destructors
Although C++ exception support encompasses just three language keywords, its implementation is complex and requires substantial runtime support from the compiler and operating system. C++ guru Herb Sutter authored a trilogy of books on the subject, spanning a total of 810 pages! The complexity primarily comes from the interplay between exceptions and two other C++ language features, namely, constructors and destructors.
Leaving exceptions aside for the moment, in the C++ object model, the compiler is obligated to insert calls to object destructors when their lifetimes end. In the context of stack-allocated local variables, this is the end of their enclosing scope. Let's consider a simple struct with a constructor and a destructor:
// Arbitrary type with a constructor and destructor
struct A {
int val;
A(int x) : val(x) { printf("A::A(%d)\n", val); }
~A() { printf("A::~A(%d)\n", val); }
};And a small function that constructs two of these objects:
void h() {
A a0(0);
A a1(1);
}If we were to execute function h, we would see the following output:
A::A(0)
A::A(1)
A::~A(1)
A::~A(0)Although the function h does not explicitly destroy its two local objects a0 and a1, we see from the output that their destructors do in fact run at the end of the function. This is because the compiler implicitly inserts those calls at the end of the objects' lifetimes:
void h() {
A a0(0);
A a1(1);
// NEW: Auto-generated destructor calls at lifetime end
a1.~A();
a0.~A();
}Exceptions and Destructors
Building from previous examples, let's investigate what happens when we introduce exceptions into the object model. Like the previous function h, function f below constructs two objects of type A. However, this time, there are three locations within f that might throw an exception, which I have labeled as points -1, 0, and 1:
void f() {
// Point -1
may_throw();
printf("-1: no exn\n");
// Construct A object a0
A a0(0);
// Point 0
may_throw();
printf("0: no exn\n");
// Construct A object a1
A a1(1);
// Point 1
may_throw();
printf("No exn anywhere %d %d\n", a0.val, a1.val);
// Auto-generated destructor calls at lifetime end
a1.~A();
a0.~A();
}In non-exceptional circumstances, i.e., when the function returns normally, execution will reach the destructor calls at the bottom. If any call to may_throw causes an exception, the function f will not execute any of its remaining code, and will instead exit early and propagate the exception into its caller. That means that, in exceptional circumstances, the destructor calls for local objects a0 and a1 at the bottom of the function will not execute.
At first glance, this might seem like a major problem. If destructor calls were skipped because of exceptions, we should expect resource leaks and other resource management issues (for example, deadlocks upon failure to release thread synchronization primitives). It is very important that the compiler still call the destructors for local objects when exceptions are thrown.
To add additional complexity, depending upon which call to may_throw throws an exception, the compiler has different obligations as to which local objects it must destroy.
- Point
-1: no objects were created, so nothing needs to be (nor should or can be) destroyed. - Point
0:a0must be destroyed, buta1must not be, sincea1was not constructed at point0. - Point
1: botha1anda0must be destroyed.
Despite these complexities, because we added printf statements to A's constructor and destructor, we can see that the compiler nevertheless manages to call the correct destructors:
// OUTPUT: exception thrown at point -1
[no output]
// OUTPUT: exception thrown at point 0
-1: no exn
A::A(0)
A::~A(0)
// OUTPUT: exception thrown at point 1
-1: no exn
A::A(0)
0: no exn
A::A(1)
A::~A(1)
A::~A(0)
// OUTPUT: no exception thrown
-1: no exn
A::A(0)
0: no exn
A::A(1)
No exn anywhere 0 1
A::~A(1)
A::~A(0)The correct destructor calls execute, despite that execution never reaches the destructor calls at the bottom of the function (which we could confirm by setting breakpoints in a debugger, for example).
Exceptions cause object lifetimes to end prematurely, and exceptional control flow bypasses the destructor calls that the compiler inserts at the end of objects' ordinary, non-exceptional lifetimes. Yet, as we have seen, the compiler also has some mechanism for invoking destructors in the presence of exceptions. What is this mechanism?
Wind states
What actually happens is that the C++ compiler emits special wind/unwind metadata to ensure that the destructors are called. These __wind and __unwind blocks are effectively invisible try and catch blocks that ensure destructors are called in the event of exceptional control flow. Internally, MSVC will transform our example akin to the following:
void f() {
may_throw();
printf("-1: no exn\n");
A a0(0);
// NEW: wind block for a0
__wind {
may_throw();
printf("0: no exn\n");
A a1(1);
// NEW: wind block for a1
__wind {
may_throw();
printf("No exn anywhere %d %d\n", a0.val, a1.val);
}
// NEW: unwind handler for a1
__unwind {
// Destroy a1 if exception at point 1
a1.~A();
}
a1.~A();
}
// NEW: unwind handler for a0
__unwind {
// Destroy a0 if exception at point 0 or 1
a0.~A();
}
a0.~A();
}Perhaps the functionality of these __wind and __unwind blocks would be clearer if we rewrote them with the standard try and catch constructs:
void f() {
// Point -1
may_throw();
printf("-1: no exn\n");
A a0(0);
// NEW: try instead of __wind
try {
may_throw();
printf("0: no exn\n");
A a1(1);
// NEW: try instead of __wind
try {
may_throw();
printf("No exn anywhere %d %d\n", a0.val, a1.val);
}
// NEW: catch instead of __unwind
catch ( ... ) {
a1.~A();
// NEW: Re-throw the exception so the next catch block gets it
throw;
}
a1.~A();
}
// NEW: catch instead of __unwind
catch ( ... ) {
a0.~A();
// NEW: Re-throw the exception out of the function
throw;
}
a0.~A();
}As we see, an __unwind handler is effectively a catch handler that catches any exception, destroys an object, and then throws the exception to the next handler up the chain. The compiler inserts them to guard the lifetimes of local stack objects in case exceptional control flow would skip their ordinary destructor calls.
Thus, we have resolved the mystery of why the compiler is able to destroy locally-allocated objects in spite of exceptional control flow and lack of try/catch blocks: because the invisibly-inserted __wind and __unwind blocks play the roles of try/catch and ensure the proper destructors are called.
Implementation, Very Briefly
This blog entry is not a treatise on how MSVC implements C++ exception machinery on the binary level. However, long-time IDA users are likely familiar with seeing messages about function chunks at the top of functions in the disassembly listing (and seeing those chunks as additional entrypoints in the graph view), as follows:
Not all function chunks come from C++ exception handlers, but in IDA up to the latest version 8.4, C++ catch and __unwind handlers are shown as function chunks such as these. (In IDA 9.0, MSVC x64 C++ catch and __unwind handlers are now defined as standalone functions, so they will no longer be shown as function chunks.)
Exceptions and Constructors
So far, we have seen that MSVC inserts so-called __unwind/__wind metadata to ensure that destructors of locally-held stack objects shall be called when exceptions are thrown. These are not the only circumstances in which such metadata is emitted.
Suppose that the constructor for a struct or class object calls functions that might throw exceptions. This idea may seem unusual, but constructors often allocate memory via calls to operator new, which throws std::bad_alloc upon allocation failure. Therefore, the constructor of any data field that calls operator new would qualify. This is another potentially problematic circumstance: any fields constructed prior would need to be destroyed before the exception were propagated out into the calling function, or else their resources would leak.
To be concrete, consider the following struct:
struct two_lists {
std::list<int> l0;
std::list<int> l1;
};Its automatically-generated constructor body would look like this:
two_lists::two_lists() {
// Point -1
this->l0.std::list<int>();
// Point 0
this->l1.std::list<int>();
};Much like the previous examples, if an exception were thrown at point 0, we would have constructed l0, and we would need to destroy it before propagating the exception into the caller. The compiler inserts __wind/__unwind metadata to ensure this happens:
two_lists::two_lists() {
this->l0.std::list<int>();
__wind {
this->l1.std::list<int>();
}
// Ensure l0 is deleted if exception while constructing l1
__unwind {
this->l0.~std::list<int>();
}
};Hex-Rays 9.0 Support
Hex-Rays 9.0 also has support for displaying wind and unwind information (although the default is not to show that metadata, for reasons we will discuss later).
For example, here is the function that we used as a running example when introducing wind constructs:
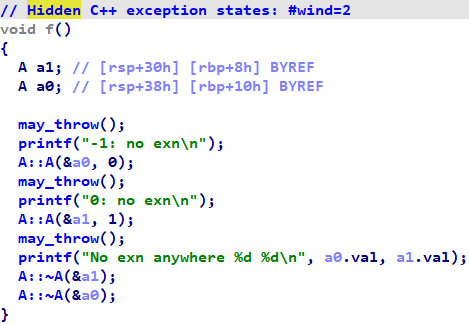
Note the message at the top informing the user that wind states were present but hidden. If one were to right-click anywhere in the function, they would see the option to show wind states:

Then the wind states would appear in the decompilation:

Reverse Engineering
Now that we have discussed the background, let's talk about when and why wind metadata is useful for reverse engineering. As we shall see, sometimes it is very useful, and sometimes less so.
As we have learned, MSVC emits wind metadata within constructors to ensure cleanup if an exception causes the constructor to terminate early. The wind metadata shows destructors for sub-objects contained within the one being constructed. This is useful because it gives three types of extra information about a struct/class and its members:
- Information about the
struct/classmember types. - Evidence of substructure nesting relationships for contained objects.
- Inheritance relationships that would otherwise be hidden.
Field Types
In the introduction, I lamented the "scavenger hunt" nature of structure reconstruction in C++. Namely, we often work with limited information about a struct, and we must follow pointers around to fill in missing details. Locating a constructor for the struct type often provides a lot of information about its overall contents, but nevertheless, important and useful information is often still absent from constructors. Locating a destructor for a struct type can help fill in the missing details, but it is not always easy to find a destructor given a constructor or vice versa. (For example, objects can be allocated anywhere in the program with operator new; to find the corresponding destructor, we would need to find a location where the object were destructed via operator delete.)
This example comes from the constructor of the top-level class used by ComRAT (for which I previously released a fully reverse engineered IDB). It calls a sub-function to return a pointer, which it writes into offset +72 in the this pointer a1.

Looking into the called function, we see an allocation of 0x30 bytes, where that same pointer is written to offsets +0 and +8 of its own allocation (hallmarks of a doubly-linked list node):

However, we are clearly missing information about this object. The allocation is 0x30 bytes in size, but the previous function only initializes its first 0x10 bytes. What is in the other 0x20 bytes? At present, we can only describe the allocated type with the following incomplete struct:
struct list_node_0x30_unknown {
list_node_0x30_unknown *_Next;
list_node_0x30_unknown *_Prev;
char gap10[0x20]; // HERE: incomplete information
};To fill in the contents of gap10, we now have to go on a scavenger hunt to find other places this struct field is used -- exactly the type of thing that makes reverse engineering C++ programs so tedious.
But, if we were to enable wind states, we would see that the constructor enters into a wind state immediately afterwards:
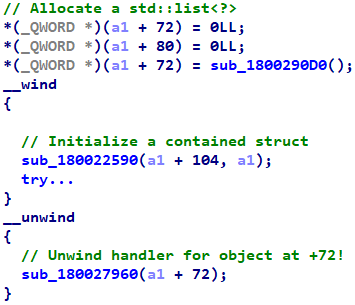
Upon looking into the unwind handler, we are immediately presented with accesses to fields within the gap10 region:

The seasoned observer will recognize those extra accesses as a std::wstring, which is 0x20 bytes. So now we can tell more specifically that offset +72 in the main struct holds a std::list<std::wstring>.
This pattern is generally true for C++ STL template containers such as vector, list, map, set, and deque. Their default constructors give limited or no information about the templated element types contained therein: only the element type's size, and in the case of vector, not even that. Conversely, destructors for STL containers call the destructors for the contained elements, thereby giving us more detailed information about the element type. By displaying wind states when analyzing the constructor, we get the best of both worlds!
Structure Nesting
Another task when recovering structs is to determine when fields are contained within nested structs. When the constructors of contained structs are inlined into the outer struct's constructor, this information is blurred. For example, the same constructor function from the last example begins by writing two QWORDs to offsets +0 and +8:

It could be the case that the outer struct contains two fields at offsets +0 and +8. It could also be the case that the outer struct begins with an inner struct at +0 that contains two fields at offsets +0 and +8. Due to inlining, we are unable to differentiate between these two possibilities.
But, the constructor enters into a wind state after initializing those fields. We can see that the this pointer itself, i.e., at offset +0, is passed to the unwind handler. Let's see what's in the unwind handler:

Because of the highlighted access, we know that the type of a1 contains a QWORD-sized field at +8. That means that a1 points to a struct that is at least 16 bytes (and seemingly at most 16 bytes, because there are no accesses beyond the one at +8). We conclude that the first two fields are not members of the outer struct, but rather, are members of a contained struct that begins at offset +0 in the outer one.
This example was simple. wind metadata can also provide rich information about inlined constructors in the presence of multiple nesting levels.
Inheritance Relationships
Yet another task in class recovery is to determine accurate inheritance relationships. One can often determine that two classes are related by looking at which VTables are installed in the constructor and/or destructor. Following cross-references to VTables can help locate related classes.
However, MSVC performs optimizations that can obscure these relationships. For example, if the VTable pointer for a given class is overwritten multiple times in a constructor, the compiler can sometimes eliminate the earlier writes, thereby obscuring the actual base classes for the class being constructed.
This is another situation where wind metadata can provide additional information. Here we see one VTable being written early in the function, and that, upon unwind, a different VTable pointer is written to the same location:

This information would not be present in the decompilation, or even the disassembly listing, were it not for us displaying the wind metadata. And now, we can exploit that information by looking at cross-references to the ancestral VTable, to discover other locations in the code that construct or destruct potentially-related class types:

Non-Constructor Functions
The conclusion of the preceding section is that wind metadata is an unambiguous win when analyzing C++ constructors. wind metadata is a rich source of information that was hiding in plain sight all along. It assists in rapidly analyzing C++ classes, assuming their constructor is known. I recommend enabling it always when you know you are looking at a constructor.
However, this blog entry introduced wind metadata in the context of non-constructor functions. For them, the advantages of displaying wind metadata is mixed. To see this, consider the following function:
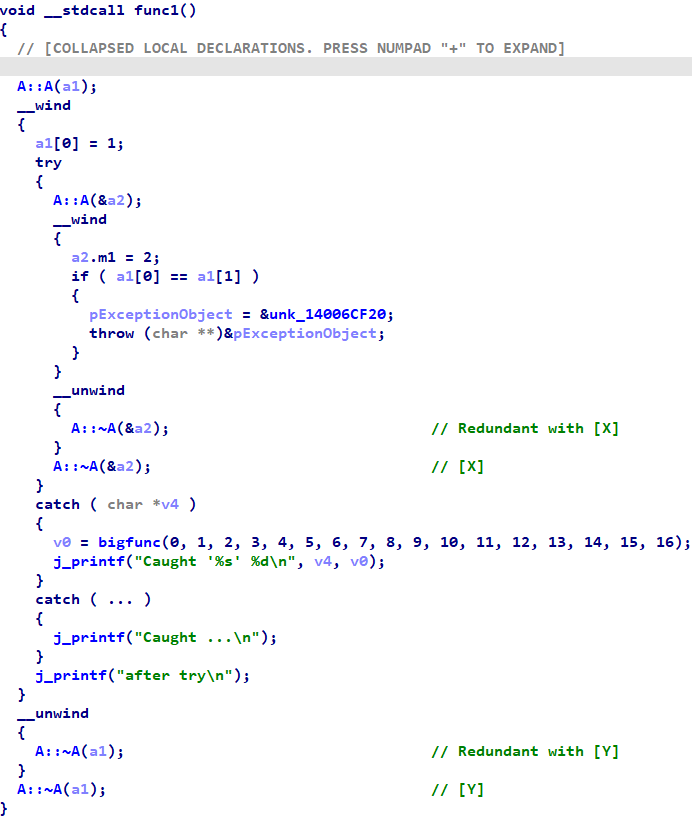
Note that there are two local objects of type A, called a1 and a2. Immediately after creating these objects, the function enters into wind states. Immediately before their lifetimes end, the function exits those wind states. However, because the outer function and the unwind handlers both call the same destructor functions, we do not gain any new information about the types of those objects. All the wind metadata really does for us here is to clarify the lifetime of those objects -- at the expense of 7 extra lines of decompiler output per wind state.
For this reason, the default behavior in Hex-Rays 9.0 is to hide wind states by default, but to inform the user that they exist, and make it easy for them to enable or disable their display.
Those caveats aside, wind metadata can still be useful when analyzing non-constructor functions, because unwind handlers are separate functions that cannot be inlined into the main function. To see this, consider the following function from ComRAT:

In this case, the destructor for a4 has been inlined into the main function (at the bottom of the snippet), but the unwind handler invokes the destructor as a dedicated function call. This is useful because we can apply a name and types to the destructor in the unwind handler. Hex-Rays can use this type to automatically apply a type to a4. Because the destructor in the function body is inlined, even if we as analysts manually recognize the destruction logic, there is nothing for us to apply a type to to cause Hex-Rays to apply type information in other functions. Moreover, because there is an actual function call, we as analysts see a nice, informative function name rather than a messy blob of inlined code. (It also makes the physical struct boundaries and the struct lifetime more clear, which can help recovering local struct types in complex functions with large statck frames.)